
5 - Parser#
The Compilation Process#

Syntax Analysis#
The syntax analysis portion of a language processor nearly always consists of 2 parts:
A low-level part called a lexical analyzer (mathematically, a finite automaton based on regular grammar)
A high-level part called a syntax analyzer, or parser (mathematically, a push-down automaton based on context-free grammar, or BNF)
Lexer (Lexical Analyzer)#
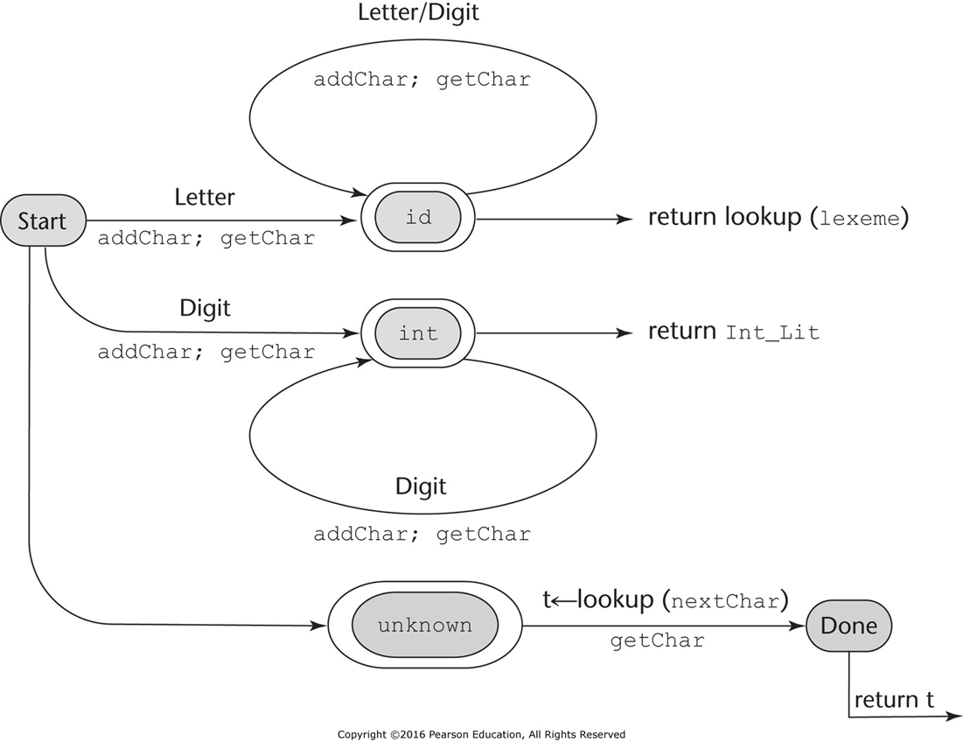
There are 2 categories of parsers:
Top-down - produce the parse tree, beginning at the root
Order is that of the leftmost derivation
Traces or builds the parse tree in preorder
Bottom-up - Produce the parse tree, beginning at the leaves
Order is that of the reverse of a rightmost derivation
Recursive-Descent Parser#
There is a subprogram for each nonterminal in the grammar, which can parse sentences that can be generated from the nonterminal.
EBNF is ideally suited for being the basis for a recursive-descent parser, because EBNF minimizes the number of rules.
An example of a grammar for simple expressions:
<expr> -> <term> {(+ | - ) <term>}
<term> -> <factor> {(* | /) <factor>}
<factor> -> id | int_constant | (<expr>)
/* Function expr parses strings in the language generated
by the rule: <expr> → <term> {(+ | -) <term>} */
void expr() {
// Parse the first term
term();
/* As long as the next token is + or -, call
lex to get the next token and parse the
next term */
while (nextToken == ADD_OP || nextToken == SUB_OP) {
lex();
term();
}
}
A nonterminal that has more than one RHS requires an initial process to determine which RHS it is to parse.
The correct RHS is chosen on the basis of the next token of input (the lookahead)
The next token is compared with the first token that can be generated by each RHS until a match is found
If not match is found, it is a syntax error
/* Function factor parses strings in the language generated
by the rule: <factor> -> id | int_constant | (<expr>) */
void factor() {
// Determine which RHS
if (nextToken == ID_CODE || nextToken == INT_CODE) {
// Just call lex to get next token
lex();
}
/* If the RHS is (<expr>) – call lex to pass over the left
parenthesis, call expr, and check for right parenthesis */
else if (nextToken == LP_CODE) {
lex();
expr();
if (nextToken == RP_CODE) {
lex();
} else {
error();
}
} /* End of else if (nextToken == ... */
else error(); /* Neither RHS matches */
}
The Left Recursion Problem: If a grammar has left recursion, either direct or indirect, it cannot be the basis for a top-down parser.
A grammar can be modified to remove direct left recursion as follows:
For each nonterminal \(A\),
Group the \(A\)-rules as \(A\) \(\rightarrow\) \(A\alpha_1\) | \(\dots\) | \(A\alpha_m\) | \(\beta_1\) | \(\beta_2\) | \(\dots\) | \(\beta_n\) where none of the \(\beta \text{s}\) begin with \(A\).
Replace the original \(A\)-rules with:
\(A \rightarrow \beta_1 A'\) | \(\beta_2 A'\) | \(\dots\) | \(\beta_n A'\)
\(A' \rightarrow \alpha_1 A'\) | \(\alpha_2 A'\) | \(\dots\) | \(\alpha_m A'\) | \(\epsilon\)
For example, \(E = E + T | T => E = T + E | T\)
The inability to determine the correct RHS on the basis of one token of lookahead:
Pairwise Disjointness Test: For each nonterminal \(A\), in the grammar that has more than one RHS, for each pair of rules, \(A \rightarrow \alpha_i\) and \(A \rightarrow \alpha_j\), it must be true that \(\text{FIRST}(\alpha_i) \ \cap \text{ FIRST}(\alpha_j) = \phi\)
\(\text{FIRST}(\alpha) = \{a | \alpha \Rightarrow * \alpha\beta\}\) (if \(\alpha \Rightarrow * \epsilon\), \(\epsilon\) is in \(\text{FIRST}(\alpha)\))
Left factoring can resolve the problem: Replace
<variable> -> identifier | identifier [<expression>]
with
<variable> -> identifier <new>
<new> -> epsilon | [<expression>]
or
<variable> -> identifier [[<expression>]]
(the our brackets are metasymbols of EBNF)
Bottom-up Parsing#
The parsing problem is finding the correct RHS in a right-sentential form to reduce to get the previous right-sentential form in the rightmost derivation.
Rightmost derivation example#
Grammar:
E -> E + T | T
T -> T * F | F
F -> (E) | id
Example:
E => E + T
=> E + T * F
=> E + T * id
=> E + F * id
=> E + id * id
=> T + id * id
=> F + id * id
=> id + id * id
Handles and (simple) phrases#
Intution about handles:
\(\beta\) is the handle of the right sentential form \(\gamma = \alpha \beta w\) if and only if \(S \Rightarrow *_{rm} \alpha Aw \Rightarrow _{rm} \alpha \beta w\).
\(\beta\) is a phrase of the right sentential form \(\gamma\) if and only if \(S \Rightarrow * \gamma = \alpha_1 A \alpha_2 \Rightarrow + \alpha_1 \beta \alpha_2\).
\(\beta\) is a simple phrase of the right sentential form \(\gamma\) if and only if \(S \Rightarrow * \gamma = \alpha_1 A \alpha_2 \Rightarrow \alpha_1 \beta \alpha_2\)
The handle of a right sentential form is its leftmost simple phrase
Given a parse tree, it is now easy to find the handle
Parsing can be thought of as handle parsing
LR Parser#
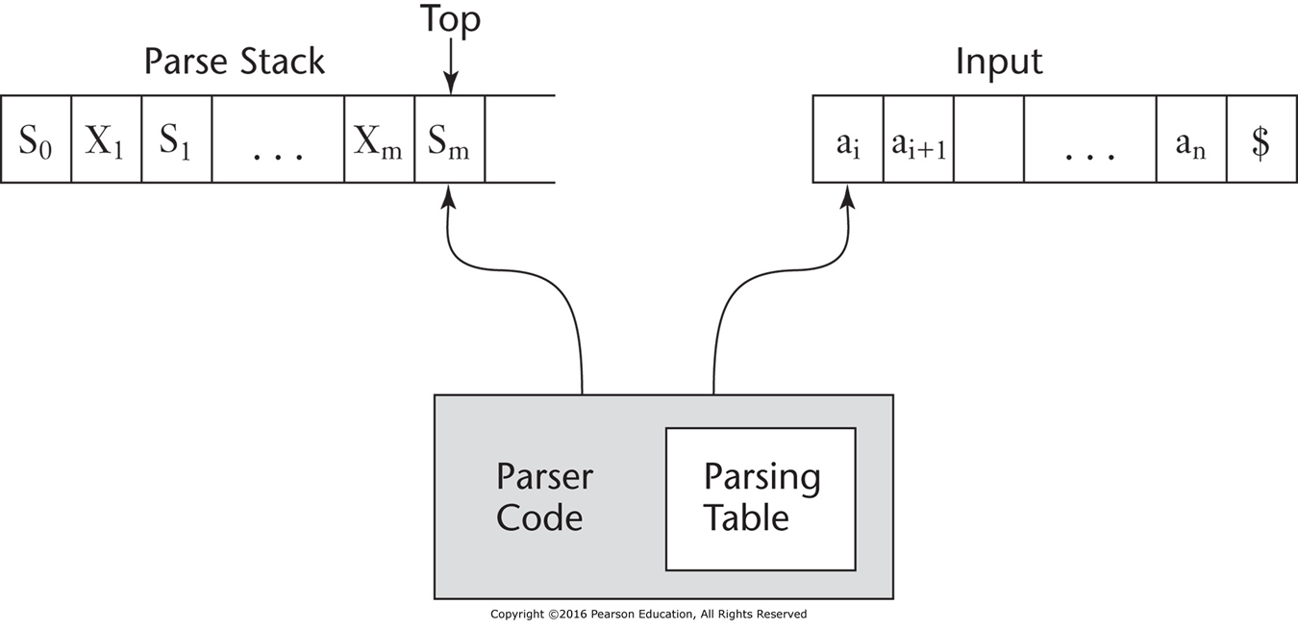
Shift-Reduce Actions#
Initial configuration: \((S_0, a_1, \dots, a_n\$)\)
Parser actions:
For a Shift, the next symbol of input is pushed onto the stack, along with the state symbol that is part of the Shift specification in the Action table.
For a Reduce, remove the handle from the stack, along with its state symbols. Push the LHS of the rule. Push the state symbol from the GOTO table, using the state symbol just below the new LHS in the stack and the LHS of the new rule as the row and column into the GOTO table.
LR Parsing Table#
A parser table can be generated from a given grammar with a tool, e.g. yacc or bison
