
24 - NoSQL Databases#
Pros and Cons of Relational Databases#
Relational Positives#
Can represent relationships in data
Easy to understand relational model/SQL
Disk-oriented storage
Indexing structures
Consistent values in database (transactions)
Relational Negatives#
RDBS can be strict and complex
Want more freedom and/or simplicity
Overhead of object to relational mapping
Want to store as is
Cannot always partition/distribute from a single database server
Want to distribute data
RDBS limited in throughput
Want higher throughput
Must scale up (expensive servers)
Want to scale out (wide - cheap servers)
RDBS providers were slow to move to the cloud
Everyone wants to use the cloud
Data Today#
Structured Data#
Information in databases
Data organized into chunks, similar entities grouped together
Descriptions for entities in groups (same format, length, etc.)
Semi-structured Data#
Data has a certain structure, but not all items are identical
Similar entities are grouped together (may have different attributes)
Schema may be mixed in with data values
Self-describing data, e.g. XML
May be displayed as a graph
Unstructured Data#
Data can be of any type, may have no format or sequence
Cannot be represented by any type of schema
HTML web pages
Video, sound, images
NoSQL#
NoSQL is rejection of the relational model. It can stand for “No to SQL” or “Not only SQL.”
There are 4 main types of NoSQL databases:
Column stores (BigTable, Hbase, Cassandra)
Key-value stores (DynamoDB, Voldemort)
Document stores (MongoDB, CouchDB)
Graph-based stores (Neo4j)
Column vs Row Stores#
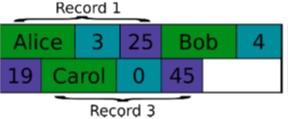
Row Storage#
A relational table is serialized as rows that are appended and flushed to disk
Whole datasets can be R/W with a I/O operation
Good locality of access on disk
Operations on columns are expensive since extra data must be read
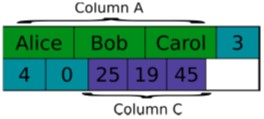
Column Storage#
Serializes tables by appending columns and flushing to disk
Operations on columns are fast and cheap
Operations on rows are expensive since extra data must be read
Good for aggregations
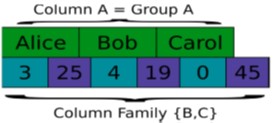
Column Storage with Locality Groups#
Like column storage, but groups columns expected to be accessed together
Store groups together and physically separated from other column groups
Google’s BigTable
Column Stores#
Stores data as tables
Advantages for data warehouses, customer relationship management (CRM) systems
More efficient for:
Aggregates
Update rows in same column
Easier to compress
Keys#
Most NoSQL databases utilize the concept of keys
In column store - called key or row key
Row keys are strings that must have the property that they can be lexicographically ordered
Each column/column family data stored along with key
HBase Column Store#
HBase is an open-source, distributed, versioned, non-relational, column-oriented data store
It is an Apache project whose goal is to provide storage for the Hadoop Distributed Computing
Data is logically organized into tables, rows, and columns
Based on Google’s BigTable
Each column family is stored in a separate file
Different sets of column families may have different properties and access patterns
Tables have one primary index: the row key
Tables sorted by row key
HBase treats everything as bites
Basic CRUD Operations#
Creating a table:
create <tablename>, <column family>, <column family>, ...Inserting data:
put <tablename>, <rowid>, <column family>:<column qualifier>, <value>Reading data (all in a table):
scan <tablename>Retrieve data (one item):
get <tablename>, <rowid>
Examples#
Creating a table called EMPLOYEE with three column families: Name, Address, and Details
create 'EMPLOYEE', 'Name', 'Address', 'Details'
Inserting data
put 'EMPLOYEE', 'row1', 'Name:Fname', 'John'put 'EMPLOYEE', 'row1', 'Name:Lname', 'Smith'put 'EMPLOYEE', 'row1', 'Name:Nickname', 'Johnny'put 'EMPLOYEE', 'row1', 'Details:Job', 'Engineer'put 'EMPLOYEE', 'row1', 'Details:Review', 'Good'